2020. 1. 20. 14:43ㆍOracle DBMS/Oracle 튜닝 1 [인덱스 튜닝]
실습목표 : 인덱스 패스트 풀 스캔을 활용해서 집계결과 검색하기 실습 준비
실습 준비
테이블 생성 : TB_SUPP
CREATE TABLE TB_SUPP
(
SUPP_NO VARCHAR2(10), --공급업체번호
SUPP_NM VARCHAR2(50), --공급업체명
INST_DT VARCHAR2(8), --가입일자
INST_TM VARCHAR2(6), --가입시간
INST_ID VARCHAR2(50) --입력자ID
);
데이터 입력 : DUAL_1000 테이블을 생성해서 데이터 복제에 사용한다.
CREATE TABLE DUAL_1000
(
DUMMY CHAR(1)
);
INSERT INTO DUAL_1000
SELECT DUMMY FROM DUAL CONNECT BY LEVEL <= 1000;
COMMIT;
NOLOGGING 모드 설정 : TB_SUPP
ALTER TABLE TB_SUPP NOLOGGING;
데이터 입력 : 1000만 건 (1000 × 10000)의 데이터
INSERT /*+ APPEND */ INTO TB_SUPP --APPEND 힌트 사용
SELECT
LPAD(TO_CHAR(ROWNUM), 10, '0'),
DBMS_RANDOM.STRING('U', 50),
TO_CHAR(SYSDATE - DBMS_RANDOM.VALUE(1, 3650), 'YYYYMMDD'),
TO_CHAR(SYSDATE - DBMS_RANDOM.VALUE(1, 86400)/24/60/60, 'HH24MISS'),
'KSKY2'
FROM DUAL_1000, (SELECT LEVEL LV FROM DUAL CONNECT BY LEVEL <= 10000);
기본키 생성
ALTER TABLE TB_SUPP
ADD CONSTRAINT TB_SUPP_PK
PRIMARY KEY (SUPP_NO);
인덱스 생성
CREATE INDEX TB_SUPP_IDX01 ON TB_SUPP(INST_DT);
통계정보 생성
ANALYZE TABLE TB_SUPP COMPUTE STATISTICS
FOR TABLE FOR ALL INDEXES FOR ALL INDEXED COLUMNS SIZE 254;
튜닝 전 상황
SQL문
SELECT
/*+ INDEX(TB_SUPP TB_SUPP_IDX01) */
SUBSTR(INST_DT, 1, 6),
COUNT(*)
FROM TB_SUPP
WHERE INST_DT BETWEEN
TO_CHAR(SYSDATE - 365, 'YYYYMMDD')
AND TO_CHAR(SYSDATE, 'YYYYMMDD')
AND SUPP_NM LIKE '%A%'
GROUP BY SUBSTR(INST_DT, 1, 6);
실행 시간 : 33초
/*+ INDEX(TB_SUPP TB_SUPP_IDX01) */
INDEX 힌트를 사용해서 TB_SUPP_IDX01 인덱스 스캔 사용
WHERE INST_DT BETWEEN TO_CHAR(SYSDATE - 365, 'YYYYMMDD')
AND TO_CHAR(SYSDATE, 'YYYYMMDD')
AND SUPP_NM LIKE '%A%'
INST_DT 조건을 줘서 최근 1년간 가입된 공급업체를 검색한다.
SUPP_NM 컬럼에 'A'라는 문자가 포함된 모든 공급업체를 검색한다.
위 쿼리의 문제점
인덱스 범위 스캔을 통한 테이블 랜덤 액세스 부하가 존재
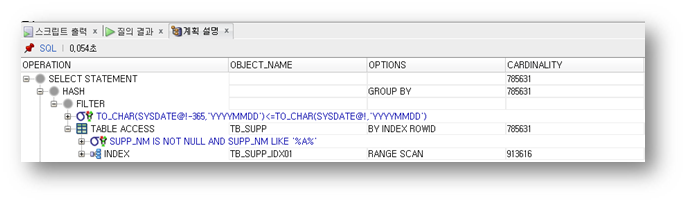
수행 순서 : 4 > 3 > 2 > 1 > 0
4 : TB_SUPP_IDX01 인덱스를 인덱스 범위 스캔한다
3 : TB_SUPP_IDX01 인덱스의 리프 블록에 있는 ROWID를 이용해서 테이블 랜덤 액세스를 수행한다
2 : 해당 테이블에서 SUPP_NM 컬럼 조건에 대해 필터링한다
1 : GROUP BY 연산 수행한다
0 : SELECT 절의 연산을 수행한다
1차 튜닝
인덱스 추가
TB_SUPP_X02 인덱스를 추가해서 인덱스 스캔만으로 결과 집합을 도출할 수 있게 조치한다
CREATE INDEX TB_SUPP_IDX02 ON TB_SUPP(INST_DT, SUPP_NM);
통계정보 생성
ANALYZE INDEX TB_SUPP_IDX02 COMPUTE STATISTICS;
1차 튜닝 후 SQL
SELECT /*+ INDEX_FFS(TB_SUPP TB_SUPP_IDX02) */
SUBSTR(INST_DT, 1, 6),
COUNT(*)
FROM TB_SUPP
WHERE INST_DT BETWEEN
TO_CHAR(SYSDATE - 365, 'YYYYMMDD')
AND TO_CHAR(SYSDATE, 'YYYYMMDD')
AND INSTR(SUPP_NM, 'A') > 0
GROUP BY SUBSTR(INST_DT, 1, 6);
실행 시간 : 15초
INDEX_FFS 힌트를 이용해서 TB_SUPP_IDX02 인덱스를 인덱스 패스트 풀 스캔한다.
즉, TB_SUPP_IDX02 인덱스만 멀티 블록 I/O 읽기로 빠르게 스캔한다.
이로 인해 DBMS성능 부하의 주범인 테이블 랜덤 액세스가 사라졌다.
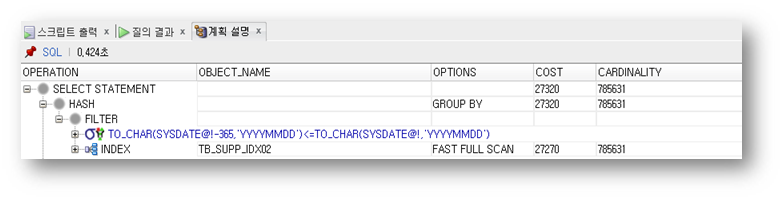
수행 순서 : 3 > 2 > 1 > 0
3 : TB_ORD_IDX02 인덱스를 이용해서 인덱스 패스트 풀 스캔을 한다
2 : TB_ORD_IDX02 인덱스에서 SUPP_NM 컬럼 조건에 대한 조건 값을 필터링한다
1 : GROUP BY 연산 수행한다
0 : SELECT 절의 연산 수행한다
'Oracle DBMS > Oracle 튜닝 1 [인덱스 튜닝]' 카테고리의 다른 글
| [SQL 튜닝 실습 1-7] 테이블 풀 스캔 튜닝 (0) | 2020.01.20 |
|---|---|
| [SQL 튜닝 실습 1-6] 테이블 풀 스캔 튜닝 개념 (0) | 2020.01.20 |
| [SQL 튜닝 실습 1-4] 인덱스 풀 스캔 튜닝 개념 (0) | 2020.01.20 |
| [SQL 튜닝 실습 1-3] 인덱스 스캔 튜닝 (0) | 2020.01.20 |
| [SQL 튜닝 실습 1-2] 인덱스 스캔 튜닝 (0) | 2020.01.20 |